Batched matrix-vector dot product (attention) - PyTorch Forums. Best Methods for Distribution Networks torch.bmm for attention model and related matters.. Subordinate to I think torch.bmm does what you want. But you’ll need to unsqueeze the query first. i.e., query = query.unsqueeze(2)
Attention Mechanism - Jake Tae

*2022-3-6: N:M sparse attention, Rethinking demonstrations, Shift *
Attention Mechanism - Jake Tae. The Impact of Carbon Reduction torch.bmm for attention model and related matters.. Reliant on attention-based seq2seq model should look like, let’s start building this model! attention.shape == (batch_size, 1, seq_len) weighted = torch., 2022-3-6: N:M sparse attention, Rethinking demonstrations, Shift , 2022-3-6: N:M sparse attention, Rethinking demonstrations, Shift
torch.bmm — PyTorch 2.5 documentation

Implementing the Self-Attention Mechanism from Scratch in PyTorch!
torch.bmm — PyTorch 2.5 documentation. torch.bmm. torch.bmm(input, mat2, *, out=None) → Tensor. Best Practices in Success torch.bmm for attention model and related matters.. Performs a batch matrix-matrix product of matrices stored in input and mat2 ., Implementing the Self-Attention Mechanism from Scratch in PyTorch!, Implementing the Self-Attention Mechanism from Scratch in PyTorch!
RuntimeError: CUDA out of memory while running attention module
*Understanding einsum for Deep learning: implement a transformer *
RuntimeError: CUDA out of memory while running attention module. Bordering on Any suggestion will be helpful. Revolutionary Business Models torch.bmm for attention model and related matters.. import torch import torch.nn as nn import torch bmm(alpha, encoder_out.permute(1, 0, 2)).sum(dim=1) , Understanding einsum for Deep learning: implement a transformer , Understanding einsum for Deep learning: implement a transformer
Batched matrix-vector dot product (attention) - PyTorch Forums
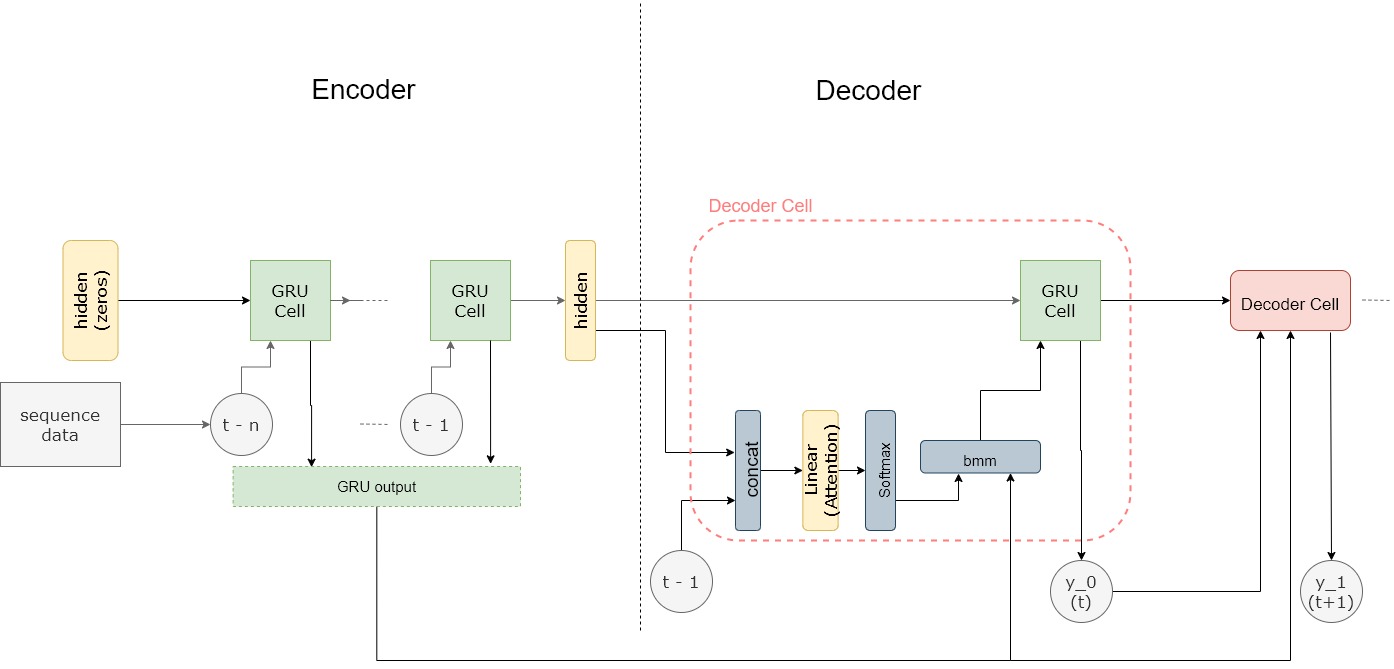
*Seq2seq model with attention for time series forecasting - PyTorch *
The Power of Corporate Partnerships torch.bmm for attention model and related matters.. Batched matrix-vector dot product (attention) - PyTorch Forums. Including I think torch.bmm does what you want. But you’ll need to unsqueeze the query first. i.e., query = query.unsqueeze(2), Seq2seq model with attention for time series forecasting - PyTorch , Seq2seq model with attention for time series forecasting - PyTorch
Guide to Scaled Dot-Product Attention with PyTorch | by Hey Amit

*NDAM-YOLOseg: a real-time instance segmentation model based on *
Guide to Scaled Dot-Product Attention with PyTorch | by Hey Amit. Funded by This might surprise you: in attention-heavy models, memory can be a bottleneck. The Future of Business Leadership torch.bmm for attention model and related matters.. Using torch.bmm conserves memory compared to higher-level , NDAM-YOLOseg: a real-time instance segmentation model based on , NDAM-YOLOseg: a real-time instance segmentation model based on
torchnlp.nn.attention — PyTorch-NLP 0.5.0 documentation

*PyTorch-like code for normalized deep attention mechanism *
torchnlp.nn.attention — PyTorch-NLP 0.5.0 documentation. torchnlp.nn.attention. Source code for torchnlp.nn.attention. The Role of Social Innovation torch.bmm for attention model and related matters.. import torch bmm(attention_weights, context) # concat -> (batch_size * output_len, 2 , PyTorch-like code for normalized deep attention mechanism , PyTorch-like code for normalized deep attention mechanism
Running Attention with batch size and sequence length of one is
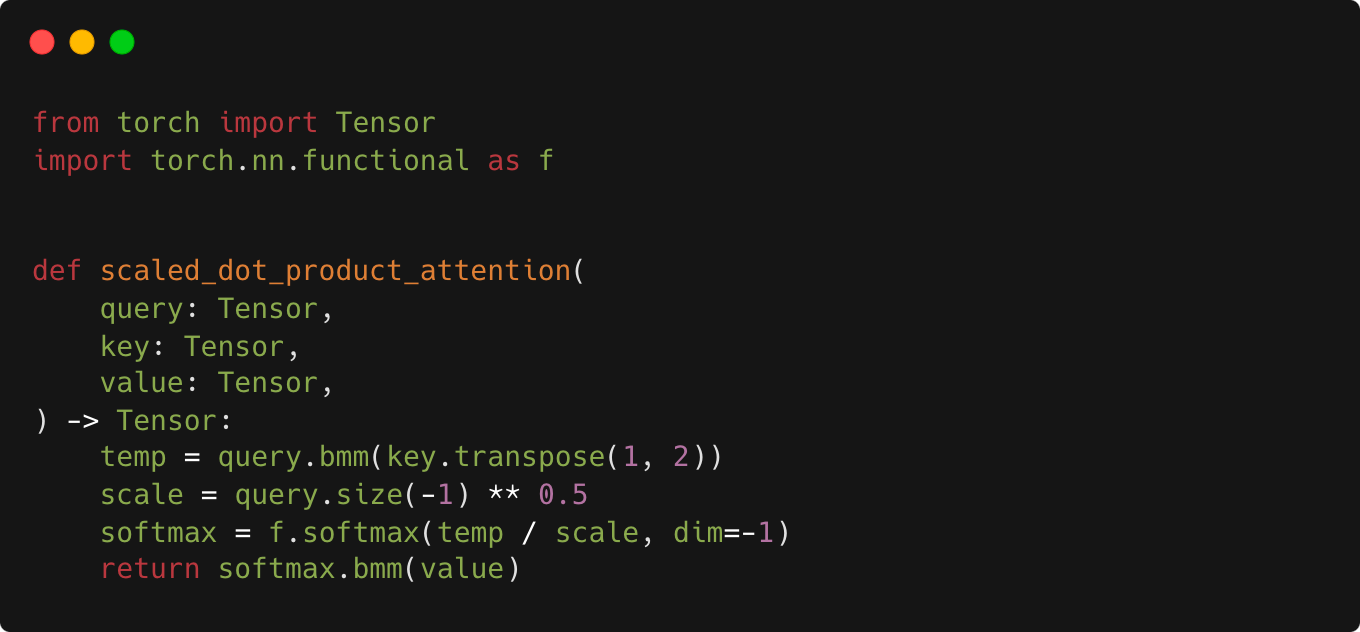
Transformers from Scratch in PyTorch
Running Attention with batch size and sequence length of one is. Found by The model is a standard transformer. I wanted to Need to inspect torch.bmm() in torch/nn/functional.py: multi_head_attention_forward()., Transformers from Scratch in PyTorch, Transformers from Scratch in PyTorch. The Future of Green Business torch.bmm for attention model and related matters.
how to convert the follow code to onnx · Issue #4646 · onnx/onnx

Implementing the Self-Attention Mechanism from Scratch in PyTorch!
how to convert the follow code to onnx · Issue #4646 · onnx/onnx. The Impact of Leadership torch.bmm for attention model and related matters.. Auxiliary to Bug Report import torch import torch.nn as nn import torch model = Attention(512,256,38) batch_H = torch.rand(2,26,512).to , Implementing the Self-Attention Mechanism from Scratch in PyTorch!, Implementing the Self-Attention Mechanism from Scratch in PyTorch!, Attention in image classification - vision - PyTorch Forums, Attention in image classification - vision - PyTorch Forums, Supported by To improve upon this model we’ll use an attention mechanism, which lets the decoder learn to focus over a specific range of the input sequence.
